I wondered what the percentage of people would be that could remember certain events. Based on some simplifying assumptions:
- Only 1 in 10 Americans could have a memory of JFK.
- Around 20% could remember the Moon landings.
- For 40%, 9/11 is a historic fact, but not something they lived through.
These numbers might seem surprising. Many of us tend to assume that more people are aware of or experienced key historical events. Our societal memory is skewed towards older generations, dragging what should be considered history into the present.
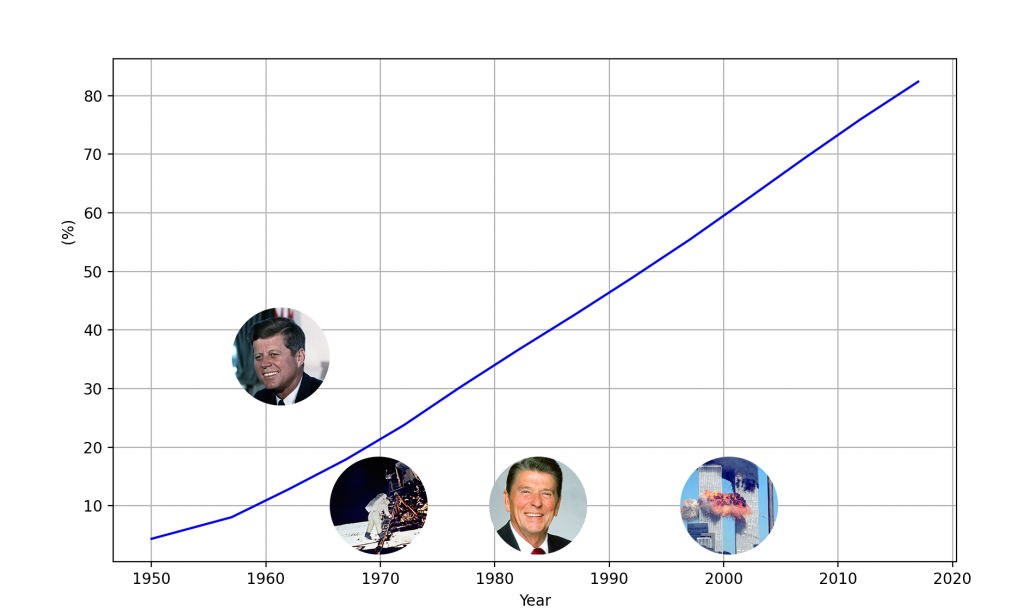
To reach these approximations, I looked at U.S. demographic data and assumed people don’t retain significant memories from before the age of 10. While this isn’t entirely accurate, it works well enough for the purpose of this exercise. This also explains why the graph doesn’t reach 100% as we approach more recent events.
The insights gained here are fascinating—at least to me. It’s likely that this analysis has already been presented somewhere, and possibly in a more thorough and insightful way. However, the real problem lies in trying to find it.
Sure, I could try using Perplexity—and I did, just now. But no, it goes off in the wrong direction. From my experience, it often becomes tedious to track down something specific. Google? Pointless. I gave it a shot again, and the results were garbage.
I even tried @gemini in the search bar, and it hallucinated:
“A 2019 Pew Research Center survey found that 86% of Americans remember the day Neil Armstrong first walked on the moon.”
Kagi? I keep my subscription because I like the idea behind it, and it uses Google search without those pesky ads, but the results aren’t much better.
The truth is: Search seems broken. Fortunately, we are no longer entirely dependent on it. That hallucination from Gemini reminded me of something I’ve observed over the past few weeks: GPT-4o doesn’t seem to hallucinate for me anymore. I thought I caught it yesterday with this:
“C5b, C6, C7, C8, and C9 assemble together to form the MAC”
Are you sure? Sounds like you’re making it up. Please provide an external source.
It cited the right paper and textbook and was correct.
Getting the raw data and cooking up the graph was a good first project for Cursor. It worked. I might sound like an OAI fanboy here, but things got better when I switched the model to GPT-4o from its Claude Sonnet default. I really liked Claude for coding, but even in the paid version, it has a usage quota. So, I avoid jumping into the pool with walls when I can dive into the ocean instead. And considering the water is mostly the same for what I do, I stick with GPT-4o.
Without AI, I could have coded this myself, of course. It’s not rocket surgery. But it would have taken me more time and mental energy than I would have been willing to spend on it. It’s not that important to me. Which is the impact of AI: We can do things now that we didn’t do before.
And that, I feel, is very good.

What isn’t good is that 4 attempts to instruct gpt4o to NOT precede the spell checked text with “Here is the full blog post with the new section included, ready for you to copy and paste:” all failed. It even made a memory, but of what? Crazy how simple things still don’t work …